您现在的位置是:网站首页> 编程资料编程资料
Keras搭建Efficientdet目标检测平台的实现思路_其它综合_
![]() 2023-05-27
725人已围观
2023-05-27
725人已围观
简介 Keras搭建Efficientdet目标检测平台的实现思路_其它综合_
学习前言
一起来看看Efficientdet的keras实现吧,顺便训练一下自己的数据。

什么是Efficientdet目标检测算法
最近,谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet,结合 EfficientNet(同样来自该团队)和新提出的 BiFPN,实现新的 SOTA 结果。

源码下载
https://github.com/bubbliiiing/efficientdet-keras
喜欢的可以点个star噢。
Efficientdet实现思路
一、预测部分
1、主干网络介绍

Efficientdet采用Efficientnet作为主干特征提取网络。EfficientNet-B0对应Efficientdet-D0;EfficientNet-B1对应Efficientdet-D1;以此类推。
EfficientNet模型具有很独特的特点,这个特点是参考其它优秀神经网络设计出来的。经典的神经网络特点如下:
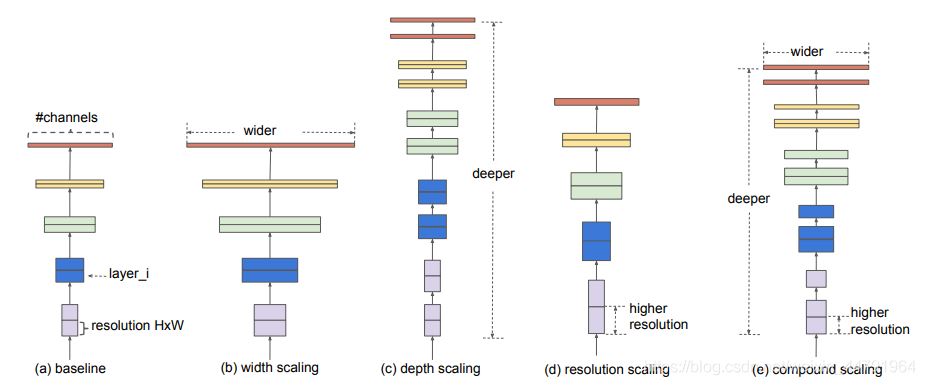
1、利用残差神经网络增大神经网络的深度,通过更深的神经网络实现特征提取。
2、改变每一层提取的特征层数,实现更多层的特征提取,得到更多的特征,提升宽度。
3、通过增大输入图片的分辨率也可以使得网络可以学习与表达的东西更加丰富,有利于提高精确度。
EfficientNet就是将这三个特点结合起来,通过一起缩放baseline模型(MobileNet中就通过缩放α实现缩放模型,不同的α有不同的模型精度,α=1时为baseline模型;ResNet其实也是有一个baseline模型,在baseline的基础上通过改变图片的深度实现不同的模型实现),同时调整深度、宽度、输入图片的分辨率完成一个优秀的网络设计。
在EfficientNet模型中,其使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率。
假设想使用 2N倍的计算资源,我们可以简单的对网络深度扩大αN倍、宽度扩大βN 、图像尺寸扩大γN倍,这里的α,β,γ都是由原来的小模型上做微小的网格搜索决定的常量系数。
如图为EfficientNet的设计思路,从三个方面同时拓充网络的特性。
本博客以Efficientnet-B0和Efficientdet-D0为例,进行Efficientdet的解析。
Efficientnet-B0由1个Stem+16个大Blocks堆叠构成,16个大Blocks可以分为1、2、2、3、3、4、1个Block。Block的通用结构如下,其总体的设计思路是Inverted residuals结构和残差结构,在3x3或者5x5网络结构前利用1x1卷积升维,在3x3或者5x5网络结构后增加了一个关于通道的注意力机制,最后利用1x1卷积降维后增加一个大残差边。

整体结构如下:

最终获得三个有效特征层传入到BIFPN当中进行下一步的操作。
from __future__ import absolute_import from __future__ import division from __future__ import print_function import os import json import math import string import collections import numpy as np from keras import backend from six.moves import xrange from nets.layers import BatchNormalization from keras import layers BASE_WEIGHTS_PATH = ( 'https://github.com/Callidior/keras-applications/' 'releases/download/efficientnet/') WEIGHTS_HASHES = { 'efficientnet-b0': ('163292582f1c6eaca8e7dc7b51b01c61' '5b0dbc0039699b4dcd0b975cc21533dc', 'c1421ad80a9fc67c2cc4000f666aa507' '89ce39eedb4e06d531b0c593890ccff3'), 'efficientnet-b1': ('d0a71ddf51ef7a0ca425bab32b7fa7f1' '6043ee598ecee73fc674d9560c8f09b0', '75de265d03ac52fa74f2f510455ba64f' '9c7c5fd96dc923cd4bfefa3d680c4b68'), 'efficientnet-b2': ('bb5451507a6418a574534aa76a91b106' 'f6b605f3b5dde0b21055694319853086', '433b60584fafba1ea3de07443b74cfd3' '2ce004a012020b07ef69e22ba8669333'), 'efficientnet-b3': ('03f1fba367f070bd2545f081cfa7f3e7' '6f5e1aa3b6f4db700f00552901e75ab9', 'c5d42eb6cfae8567b418ad3845cfd63a' 'a48b87f1bd5df8658a49375a9f3135c7'), 'efficientnet-b4': ('98852de93f74d9833c8640474b2c698d' 'b45ec60690c75b3bacb1845e907bf94f', '7942c1407ff1feb34113995864970cd4' 'd9d91ea64877e8d9c38b6c1e0767c411'), 'efficientnet-b5': ('30172f1d45f9b8a41352d4219bf930ee' '3339025fd26ab314a817ba8918fefc7d', '9d197bc2bfe29165c10a2af8c2ebc675' '07f5d70456f09e584c71b822941b1952'), 'efficientnet-b6': ('f5270466747753485a082092ac9939ca' 'a546eb3f09edca6d6fff842cad938720', '1d0923bb038f2f8060faaf0a0449db4b' '96549a881747b7c7678724ac79f427ed'), 'efficientnet-b7': ('876a41319980638fa597acbbf956a82d' '10819531ff2dcb1a52277f10c7aefa1a', '60b56ff3a8daccc8d96edfd40b204c11' '3e51748da657afd58034d54d3cec2bac') } BlockArgs = collections.namedtuple('BlockArgs', [ 'kernel_size', 'num_repeat', 'input_filters', 'output_filters', 'expand_ratio', 'id_skip', 'strides', 'se_ratio' ]) # defaults will be a public argument for namedtuple in Python 3.7 # https://docs.python.org/3/library/collections.html#collections.namedtuple BlockArgs.__new__.__defaults__ = (None,) * len(BlockArgs._fields) DEFAULT_BLOCKS_ARGS = [ BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16, expand_ratio=1, id_skip=True, strides=[1, 1], se_ratio=0.25), BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24, expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25), BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40, expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25), BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80, expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25), BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112, expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25), BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192, expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25), BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320, expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25) ] CONV_KERNEL_INITIALIZER = { 'class_name': 'VarianceScaling', 'config': { 'scale': 2.0, 'mode': 'fan_out', # EfficientNet actually uses an untruncated normal distribution for # initializing conv layers, but keras.initializers.VarianceScaling use # a truncated distribution. # We decided against a custom initializer for better serializability. 'distribution': 'normal' } } DENSE_KERNEL_INITIALIZER = { 'class_name': 'VarianceScaling', 'config': { 'scale': 1. / 3., 'mode': 'fan_out', 'distribution': 'uniform' } } def get_swish(): def swish(x): return x * backend.sigmoid(x) return swish def get_dropout(): class FixedDropout(layers.Dropout): def _get_noise_shape(self, inputs): if self.noise_shape is None: return self.noise_shape symbolic_shape = backend.shape(inputs) noise_shape = [symbolic_shape[axis] if shape is None else shape for axis, shape in enumerate(self.noise_shape)] return tuple(noise_shape) return FixedDropout def round_filters(filters, width_coefficient, depth_divisor): filters *= width_coefficient new_filters = int(filters + depth_divisor / 2) // depth_divisor * depth_divisor new_filters = max(depth_divisor, new_filters) if new_filters < 0.9 * filters: new_filters += depth_divisor return int(new_filters) def round_repeats(repeats, depth_coefficient): return int(math.ceil(depth_coefficient * repeats)) def mb_conv_block(inputs, block_args, activation, drop_rate=None, prefix='', freeze_bn=False): has_se = (block_args.se_ratio is not None) and (0 < block_args.se_ratio <= 1) bn_axis = 3 Dropout = get_dropout() filters = block_args.input_filters * block_args.expand_ratio if block_args.expand_ratio != 1: x = layers.Conv2D(filters, 1, padding='same', use_bias=False, kernel_initializer=CONV_KERNEL_INITIALIZER, name=prefix + 'expand_conv')(inputs) x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'expand_bn')(x) x = layers.Activation(activation, name=prefix + 'expand_activation')(x) else: x = inputs # Depthwise Convolution x = layers.DepthwiseConv2D(block_args.kernel_size, strides=block_args.strides, padding='same', use_bias=False, depthwise_initializer=CONV_KERNEL_INITIALIZER, name=prefix + 'dwconv')(x) x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'bn')(x) x = layers.Activation(activation, name=prefix + 'activation')(x) # Squeeze and Excitation phase if has_se: num_reduced_filters = max(1, int( block_args.input_filters * block_args.se_ratio )) se_tensor = layers.GlobalAveragePooling2D(name=prefix + 'se_squeeze')(x) target_shape = (1, 1, filters) if backend.image_data_format() == 'channels_last' else (filters, 1, 1) se_tensor = layers.Reshape(target_shape, name=prefix + 'se_reshape')(se_tensor) se_tensor = layers.Conv2D(num_reduced_filters, 1, activation=activation, padding='same', use_bias=True, kernel_initializer=CONV_KERNEL_INITIALIZER, name=prefix + 'se_reduce')(se_tensor) se_tensor = layers.Conv2D(filters, 1, activation='sigmoid', padding='same', use_bias=True, kernel_initializer=CONV_KERNEL_INITIALIZER, name=prefix + 'se_expand')(se_tensor) if backend.backend() == 'theano': # For the Theano backend, we have to explicitly make # the excitation weights broadcastable. pattern = ([True, True, True, False] if backend.image_data_format() == 'channels_last' else [True, False, True, True]) se_tensor = layers.Lambda( lambda x: backend.pattern_broadcast(x, pattern), name=prefix + 'se_broadcast')(se_tensor) x = layers.multiply([x, se_tensor], name=prefix + 'se_excite') # Output phase x = layers.Conv2D(block_args.output_filters, 1, padding='same', use_bias=False, kernel_initializer=CONV_KERNEL_INITIALIZER, name=prefix + 'project_conv')(x) # x = BatchNormalization(freeze=freeze_bn, axis=bn_axis, name=prefix + 'project_bn')(x) x = layers.BatchNormalization(axis=bn_axis, name=prefix + 'project_bn')(x) if block_args.id_skip and all( s == 1 for s in block_args.strides ) and block_args.input_filters == block_args.output_filters: if drop_rate and (drop_rate > 0): x = Dropout(drop_rate, noise_shape=(None, 1, 1, 1), name=prefix + 'drop')(x) x = layers.add([x, inputs], name=prefix + 'add') return x def EfficientNet(width_coefficient, depth_coefficient, default_resolution, dropout_rate=0.2, drop_connect_rate=0.2, depth_divisor=8, blocks_args=DEFAULT_BLOCKS_ARGS, model_name='efficientnet', include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000, freeze_bn=False, **kwargs): features = [] if input_tensor is None: img_
点击排行
本栏推荐





